OLTP - Online Transactional Processing
OLAP - Online Analytical Processing
We can divide the Datawarehouse storage into 2 sections, i.e, transactional (OLTP) and analytical (OLAP).
As the name suggests, OLTP stores the transactional data and OLAP is used to store the analytical data. We can assume that OLTP systems provide source data to data warehouses, whereas OLAP systems help to analyze it.
Let us take an example for explaining this point:
While discussing the concept of staging area, we took an example of a telecom company datawarehouse.
In that case, suppose you are a mobile phone user, all the individual transaction you do become source for ultimately loading the Datawarehouse.
The individual action (like making a call, sending an SMS, sending an MMS etc) becomes a transaction, which will be stored in an OLTP system.
And again as discussed in Staging area post, after 1 month the data in OLTP systems will be summarized and loaded into the OLAP systems.
Ironically, staging area and OLTP systems are nothing the same. They store the transactional data for a specific interval of time and than after summation the data is loaded in OLAP (that's Datawarehouse) where the data seat's for analysis purpose.

-OLAP (On-line Analytical Processing): It is characterized by relatively low volume of transactions. Queries are often very complex and involve aggregations. For OLAP systems a response time is an effectiveness measure. OLAP applications are widely used by Data Mining techniques. In OLAP database there is aggregated, historical data, stored in multi-dimensional schema's (usually star schema).
Based on the above discussion, the below differentiation will help you understand the difference between the OLTP and OLAP.

Hope this explains everything to be understood about the OLAP and OLTP systems.
Now let's talk about the different types of OLAP systems available.
Before moving just keep one thing in mind, this difference is only related to the technology which is used to store the data. There are various ways/technologies available for data storage.



OLAP - Online Analytical Processing
We can divide the Datawarehouse storage into 2 sections, i.e, transactional (OLTP) and analytical (OLAP).
As the name suggests, OLTP stores the transactional data and OLAP is used to store the analytical data. We can assume that OLTP systems provide source data to data warehouses, whereas OLAP systems help to analyze it.
Let us take an example for explaining this point:
While discussing the concept of staging area, we took an example of a telecom company datawarehouse.
In that case, suppose you are a mobile phone user, all the individual transaction you do become source for ultimately loading the Datawarehouse.
The individual action (like making a call, sending an SMS, sending an MMS etc) becomes a transaction, which will be stored in an OLTP system.
And again as discussed in Staging area post, after 1 month the data in OLTP systems will be summarized and loaded into the OLAP systems.
Ironically, staging area and OLTP systems are nothing the same. They store the transactional data for a specific interval of time and than after summation the data is loaded in OLAP (that's Datawarehouse) where the data seat's for analysis purpose.

Fig, 1(a)
-OLTP (On-line Transaction Processing): It is characterized by a large number of
short on-line transactions (INSERT, UPDATE, DELETE). The main emphasis for OLTP
systems is put on very fast query processing, maintaining data integrity in multi-access
environments and an effectiveness measured by number of transactions per
second. In OLTP database there is detailed and current data, and schema used to
store transactional databases is the entity model (usually 3NF).
-OLAP (On-line Analytical Processing): It is characterized by relatively low volume of transactions. Queries are often very complex and involve aggregations. For OLAP systems a response time is an effectiveness measure. OLAP applications are widely used by Data Mining techniques. In OLAP database there is aggregated, historical data, stored in multi-dimensional schema's (usually star schema).
Based on the above discussion, the below differentiation will help you understand the difference between the OLTP and OLAP.

Hope this explains everything to be understood about the OLAP and OLTP systems.
Now let's talk about the different types of OLAP systems available.
Before moving just keep one thing in mind, this difference is only related to the technology which is used to store the data. There are various ways/technologies available for data storage.
Depending on the underlying technology
used, OLAP systems can be broadly divided into
1. MOLAP(Multidimensional OLAP),
2. ROLAP (Relational OLAP),
3. HOLAP (Hybrid OLAP).
Hybrid OLAP (HOLAP) refers to technologies that combine MOLAP and ROLAP.
MOLAP: As the name suggests, the data is stored in

Fig, 2(a)
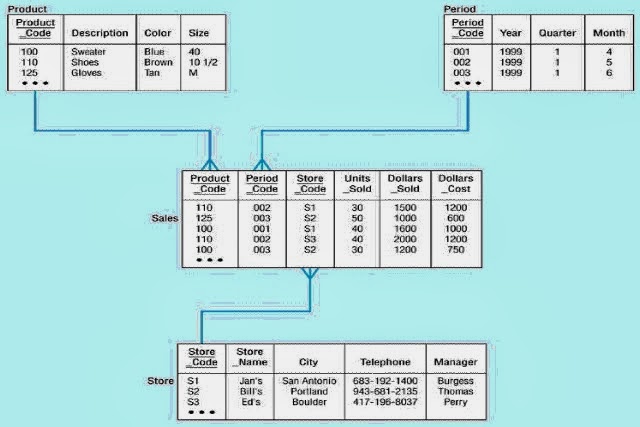
In the Fig, 2(a), see how the data is stored in the form of a cube against the data in a relational systems. As you can see multidimensional cube removes the duplication by storing the data in form of multiple dimensions, where in saving the space.

Fig, 2(b)
The Fig, 2(b), represents the similar concept but at a 3 dimensional level. Here prodID becomes one dimension, storeid becomes 2nd Dimension and date is the 3rd dimension. Based on the 3 dimension the value of amt is stored. This clearly indicates that the space utilization is better.
We can now, logically cut the cube across dimensions so as to get the value for a particular dimension. Like we can slice the cute in Fig, 2(b) vertically to get the data related to prodid, and the cube can be sliced horizontally to get the data related to storeid. This concept is called as SLICING and DICING.

Fig, 3(a)
Advantages:
-- Excellent performance: MOLAP cubes are
built for fast data retrieval, and is optimal for slicing and dicing
operations.
-- MOLAP can perform complex calculations. All
calculations have been pre-generated when the cube is created. So when we create the cube the calculations are already generated, so while retrieving it becomes very fast. Hence, complex
calculations return quickly.
Disadvantages:
-- Limited in the amount of data it can
handle: Because all calculations are performed when the cube is built, it is
not possible to include a large amount of data in the cube itself. This is not
to say that the data in the cube cannot be derived from a large amount of data.
Indeed, this is possible. But in this case, only summary-level information will
be included in the cube itself.
-- Requires additional investment: Cube
technology are often proprietary and do not already exist in the organization.
Therefore, to adopt MOLAP technology, chances are additional investments in
human and capital resources are needed.
ROLAP : As the name suggests, the data is stored in Relational tables.
This methodology relies on manipulating
the data stored in the relational database to give the appearance of
traditional OLAP's slicing and dicing functionality. In essence, each action of
slicing and dicing is equivalent to adding a "WHERE" clause in the
SQL statement.
Advantages:
-- Can handle large amounts of data: The
data size limitation of ROLAP technology is the limitation on data size of the
underlying relational database. In other words, ROLAP itself places no
limitation on data amount.
-- Can leverage functionality inherent
in the relational database: Often, relational database already comes with a
host of functionalities. ROLAP technologies, since they sit on top of the
relational database, can therefore leverage these functionalities.
Disadvantages:
-- Performance can be slow: Because each
ROLAP report is essentially a SQL query (or multiple SQL queries) in the
relational database, the query time can be long if the underlying data size is
large.
-- Limited by SQL functionalities:
Because ROLAP technology mainly relies on generating SQL statements to query
the relational database, and SQL statements do not fit all needs (for example,
it is difficult to perform complex calculations using SQL), ROLAP technologies
are therefore traditionally limited by what SQL can do. ROLAP vendors have
mitigated this risk by building into the tool out-of-the-box complex functions
as well as the ability to allow users to define their own functions.
HOLAP: HOLAP technologies attempt to combine
the advantages of MOLAP and ROLAP. For summary-type information, HOLAP leverages
cube technology for faster performance. When detail information is needed,
HOLAP can "drill through" from the cube into the underlying
relational data.
As you can understand now, OLAP can be create using various technologies.